
Java outperforms Go in Apache Beam: Performance insights with Spark and Flink runners

Alan Sipiorski

16.09.2025
Conclusion
The reason Java outperforms Go in Apache Beam processing is mostly because Go can only run Beam pipelines using Portable Runners, unlike Java that uses Classic Runners (which support all JVM-based languages). Portable runners provide cross-language and cross-framework portability but may not leverage language-specific optimizations as effectively as Classic Runners do. This is the example of interoperability overhead which affects the performance up to x2 in both real and processing time in the pipeline executions.
The comparison of Apache runners showed that Spark handles real-time execution more efficiently than Flink.
Both test scenarios were related to batch processing, which is surprising, because it is said that Apache Flink is generally recognized as a stream processing system, while Apache Spark is viewed as a batch processing dedicated tool. Nonetheless both Spark and Flink effectively support batch and stream processing.
It is said that Spark has a more mature community, better detailed documentation and richer ecosystem. Meanwhile Flink has higher throughput and lower latency processing, and more advanced stream processing capabilities. Analyzing our results we can conclude that Flink remains a strong choice even for batch processing scenarios.
Ultimately, the choice between Java and Go, as well as Spark and Flink runners, depends on the specific usage.
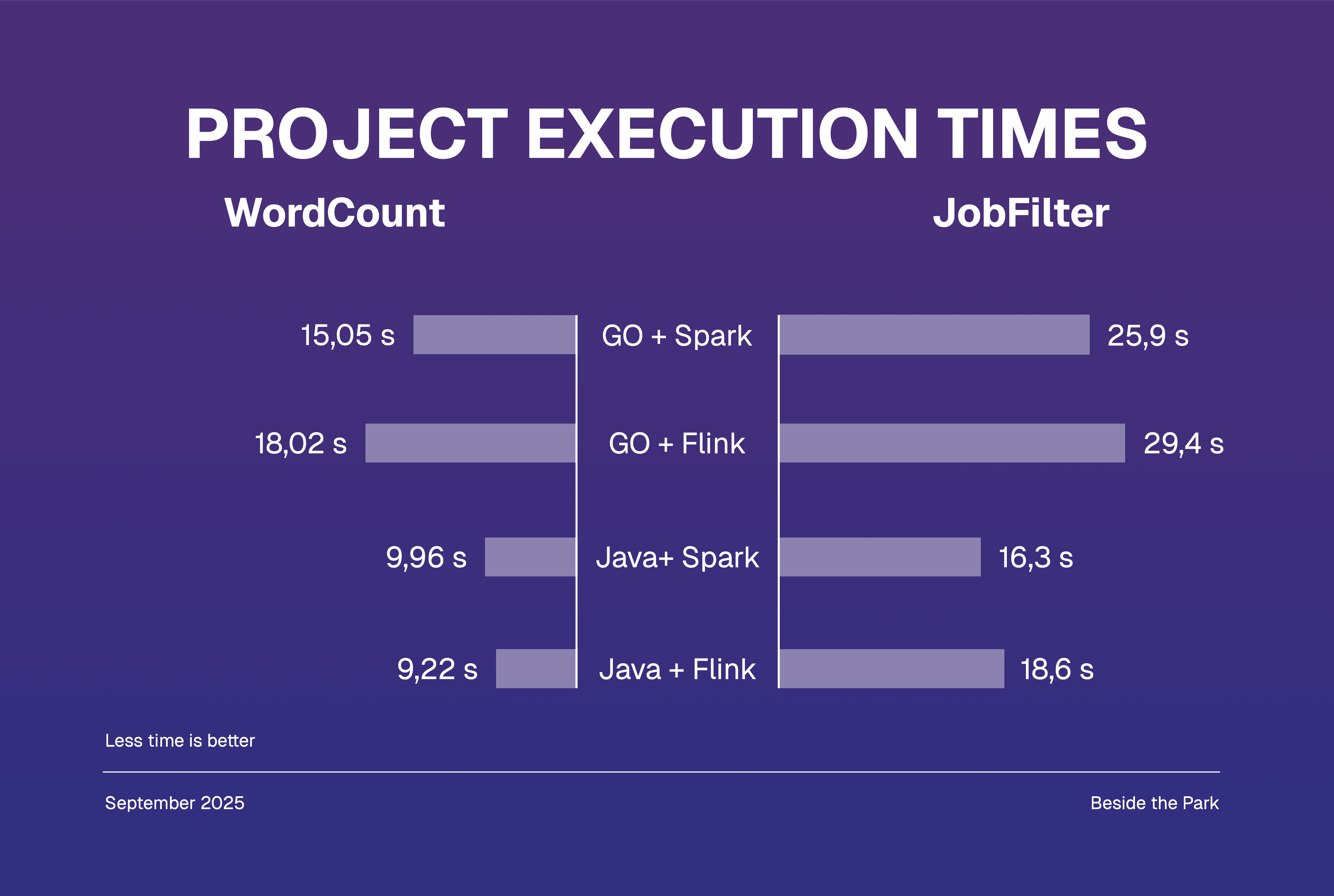
Table of Contents
Purpose of research: Java vs Go, Spark vs Flink
There is a common belief that Go generally outperforms Java in terms of speed and efficiency. This article aims to verify that theory within the context of Apache Beam batch processing. Alongside language performance evaluation, we analyzed two popular Apache Beam runners, Spark and Flink, in order to test their impact on overall speed, efficiency and practicality.
Our goal is to provide insights into how to choose the right programming language and runner for Apache Beam Big Data processing tasks.
A powerful tool: Apache Beam
Apache Beam is a tool created with efficient data processing in mind. It is an open-source and unified programming model that supports a variety of runners responsible for executing data pipelines, while not being dependent on a one specific backend system or programming language. Beam is a great, dynamic tool that allows developers to use it for either stream or batch processing of very large datasets.
Example languages that Apache Beam supports:
- Java
- Python
- Go
- TypeScript
- … many more
Example runners that Apache Beam can use for executions:
- Direct runner
- Apache Spark
- Apache Flink
- Google Cloud Dataflow
What is a Beam Pipeline and how does it work?
A Pipeline, in the context of Apache Beam, is a set of instructions that defines a data processing workflow. An example of how a pipeline can work is the following: read data from Google Cloud Storage, apply transformations on the data, and then output the processed results.
Executing the workflow gives Beam a signal that it first needs to translate the pipeline into the parts that can be executed by a chosen runner (for ex. Apache Spark or Apache Flink). The runner then orchestrates the next steps of the execution.
Once the pipeline is defined, Apache Beam abstracts the complexities of parallel data processing by breaking down the pipeline into smaller, manageable components that handle the rest.
Why should you use Apache Beam?
By using Beam, you can build flexible and portable data processing pipelines that will work well across different execution environments. It was created with the premise of being a unified model where one code can be written in Java, Python or even Go, which means that written once, the pipeline can be also executed in the same way in Apache Spark or in Apache Flink without any changes.
In the world of big data, Beam is a very powerful tool which can maximize large information handling and processing.
Execution runners: Apache Spark and Apache Flink
Spark
Considered as “The most widely-used engine for scalable computing”, Apache Spark is a very popular multi-language engine, used for execution of data engineering, data science and machine learning. Spark job applications can be written in multiple programming languages such as Java, Scala or even Python. The engine itself supports both batch and stream data processing.
Spark can also act as an Apache Beam runner, for executing its pipelines. However, the classic Spark Runner can only (as of today) support JVM-based languages (ex. Java) and for the rest, the Portable Runner comes in handy.
Flink
Apache Flink is also a popular framework and distributed processing engine. Created for stateful computations over unbounded - streams and bounded - batches data and to perform computations at in-memory speed and at any scale, with high availability. It’s a very powerful tool that is currently being used for many big companies such as AWS, eBay, Pinterest, Uber etc. Like Spark, Flink can be programmed with multiple languages: SQL, Java, Scala, Python and other JVM languages, for example Kotlin.
Flink is mostly used as a tool that processes all kinds of total time data, from fraud and anomaly detections, to reading and monitoring large system logs.
Just like Apache Spark, Flink can also act as an Apache Beam pipeline execution runner. The usage is exactly the same, if you want to use it with JVM-based languages you can go with a classic Flink Runner, for the rest, you need to use the Portable Runner.
Go and Java
Go
Go is generally considered a faster language than Java, and in most cases, this is true. It is an open-source procedural programming language developed by Google. Features like strong concurrency support, a built-in garbage collector, and fast compilation times are what people appreciate most. Although its community is smaller than Java's, it is still growing. Many large companies, including Google, PayPal, Netflix, and X (formerly Twitter) confidently use Go as one of the programming languages and tools for their projects.
Java
On the other hand, Java is one of the most popular programming languages today. The vast number of applications coded in Java results in a high support and a large community. Whether developing a web application, game, or big data application. Inspired by C and C++, it inherits many features, though it prioritizes portability and security at the cost of a slightly slower performance.
The Comparison
Performance measurements were carried out for WordCount and JobFilter projects.
Used technologies
- Apache Beam 2.56.0
- Apache Spark 3.2.2
- Apache Flink 1.16
- Java 11
- Go 1.22
- Docker
Projects and used datasets
WordCount is a project that can ingest any large text file to first extract the words, then count them and finally write them to a new file, with a number of each occurance.
For our first wordcount scenario we used a 92 kB file generated by the lorem ipsum generator, consisting of around 13620 words in total.
The second testing case dataset was prepared using the content of the book Crime and Punishment by Fyodor Dostoyevsky - around 1.2 MB.
JobFilter on the other hand loads a specific pre-processed csv file, downloaded from kaggle: 1.3M Linkedin Jobs & Skills (2024) - 1296381 lines and 672 MB.
The prepared data consists of two columns:
- job_link - url address to the job advertisement on the Linkedin platform
- job_skills - list of skills required for the specific job
This project takes a list of job skills as an argument for filtering out the appropriate job offers. It reads the file content, ingests it and parses the lines, then using the list of passed strings it filters out correct offers, formats the output and writes it to the new file.
Each project was written both in Java and Go, each combination of language + runner was executed 5 times, the average time was noted and presented below.
WordCount execution time results
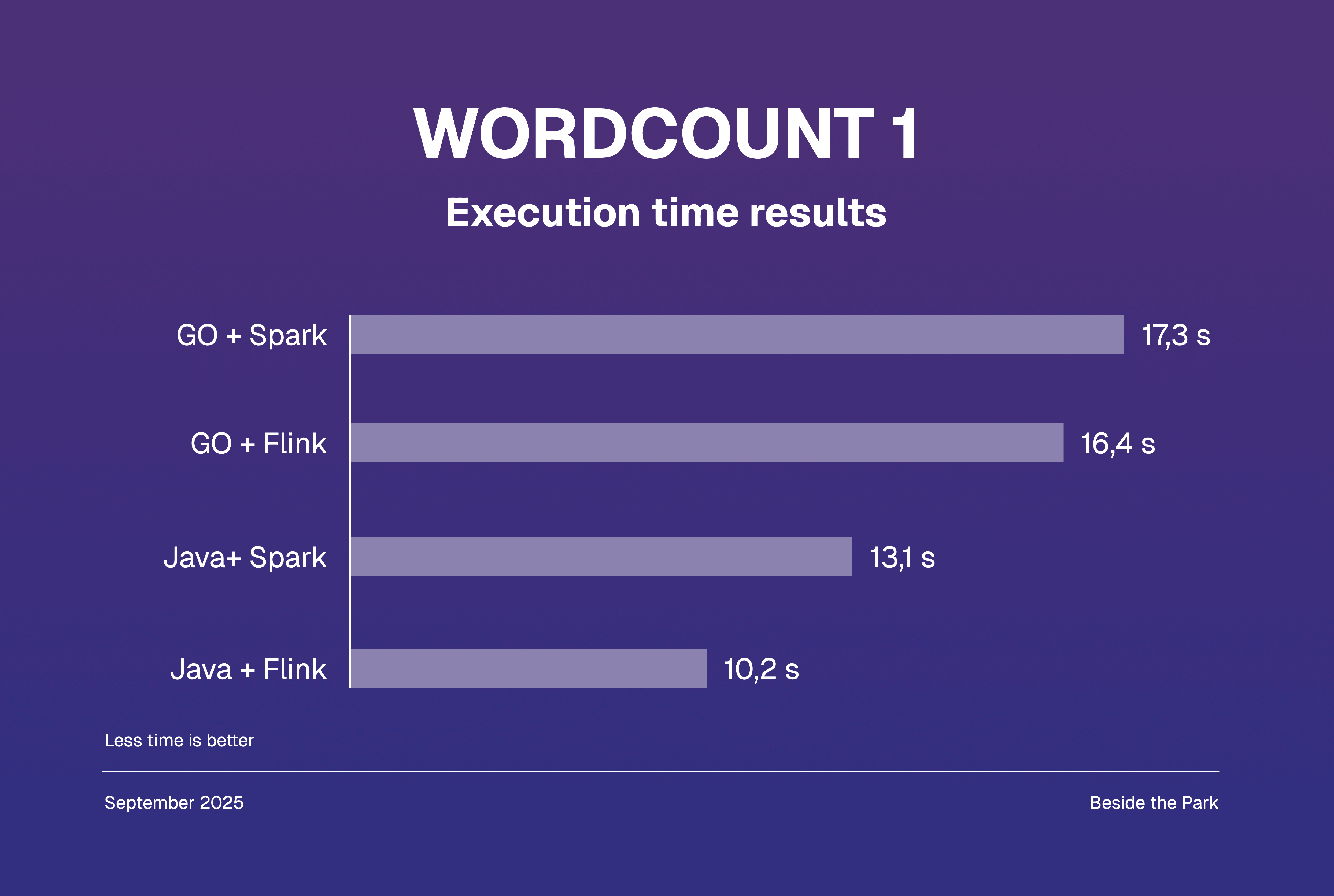
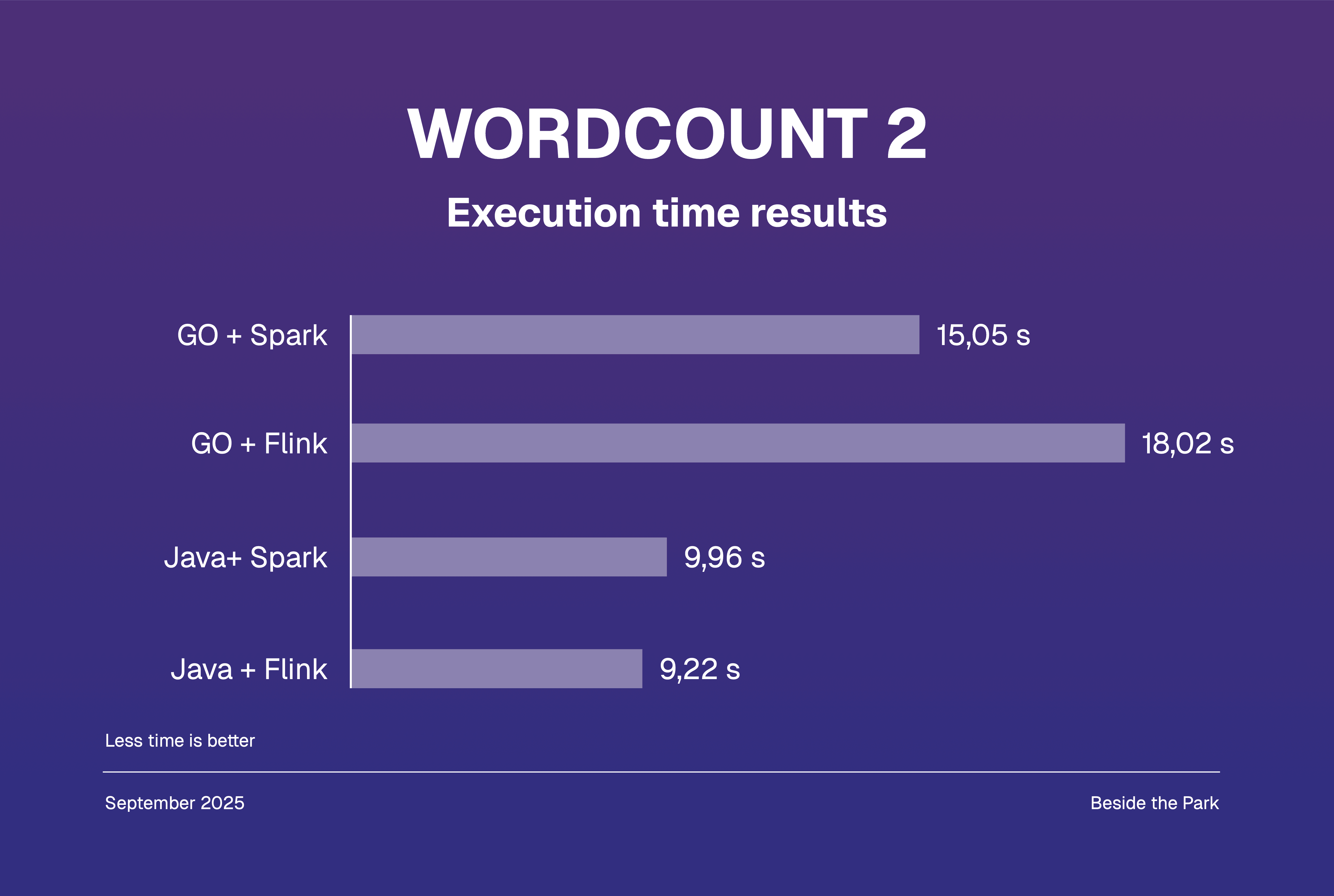
In both cases we learned that Java is strongly outperforming Go, what’s more interesting is that it is not clear whether Spark is faster than Flink as it is commonly said, though it’s mostly a matter of approximately 1-2 seconds.
JobFilter execution time results
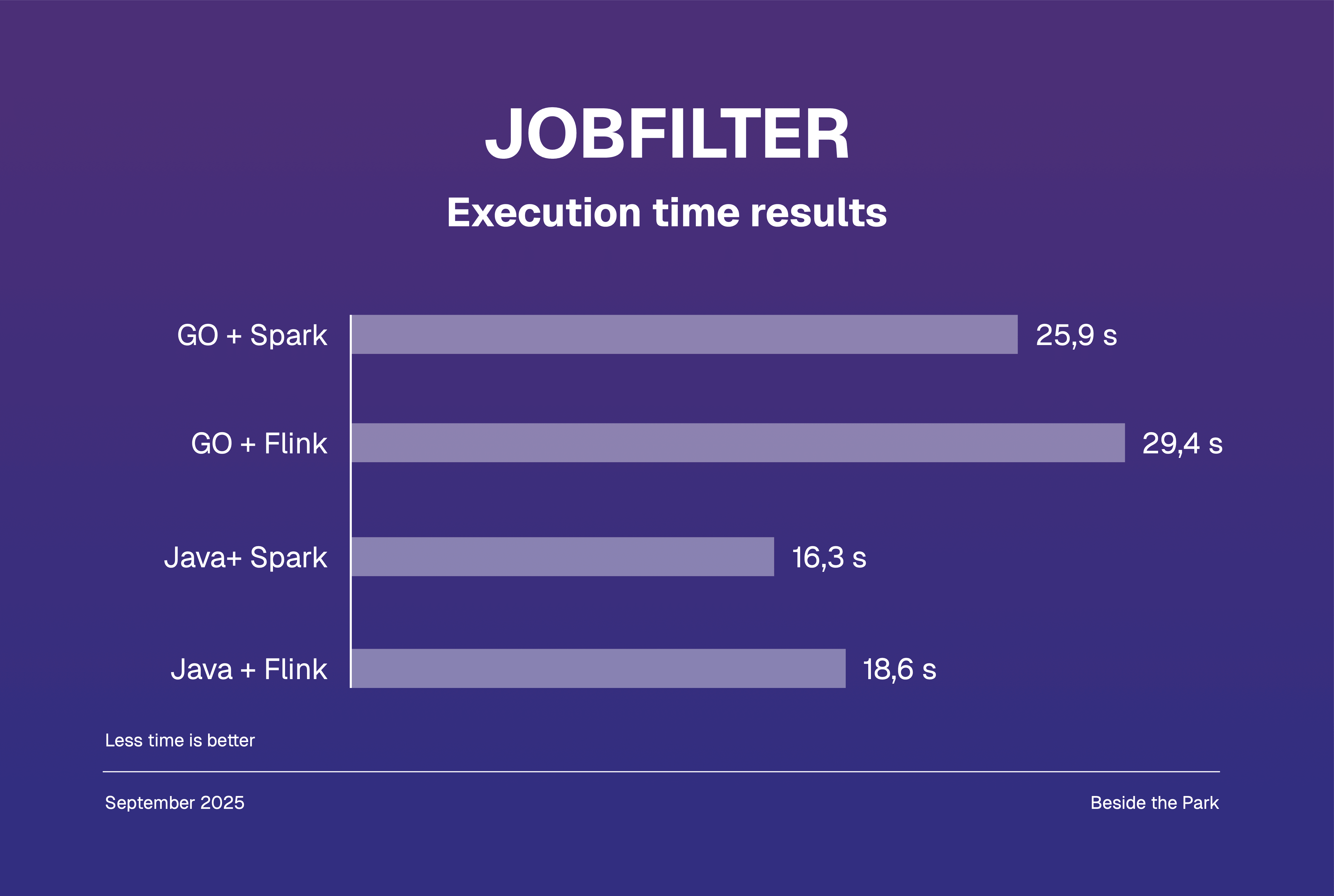
Again, Java came out visibly better from the battle with Go, though this time Spark’s execution time was always lower than Flink’s, for both programming languages. The dataset we used this time was exceptionally larger than previously, about x600 times bigger.
General conclusions
After testing Apache Beam with different programming languages and execution runners, some interesting patterns emerged:
- Java consistently outperformed Go in every test, often by a significant margin. This is because Java can use Classic Runners, optimized for JVM. Portable Runners are great for cross-language flexibility, but they don’t have the same level of optimization that Classic Runners do. As a result, Java pipelines were up to twice as fast as those written in Go.
- The results between Apache Spark and Apache Flink were a bit more nuanced. Spark generally came out ahead, especially with larger datasets like the one used in the JobFilter project. However, Flink wasn’t far behind, particularly with smaller datasets.
In the end, Apache Beam is a flexible and powerful tool for big data processing, but the language and runner chosen can significantly impact performance, especially when working with large datasets.
References
https://beam.apache.org/documentation
https://atlan.com/batch-processing-vs-stream-processing
https://blog.allegro.tech/2021/06/1-task-2-solutions-spark-or-beam.html
https://www.datacamp.com/blog/flink-vs-spark
https://cwiki.apache.org/confluence/display/BEAM/Design+Documents